May 21, 2024 at 03:25 PMJavaScript/JSOpenAIChatGPTWebSocketsAudioTTSSTTTutorial
In this tutorial, I will present how to create a simple popup AI chat that can
be added to any website. The client will be able to reply to the chat by typing
and speaking to the bot.
We will be using tools from OpenAI for the AI functionalities. For the chat, we
will use ChatGPT, for the STT (speech-to-text), Whisper, and for the TTS
(text-to-speech) their TTS.
I will show multiple methods to implement the app, starting from a naive, or
basic, method to a better, but also more complex, method.
The application will be implemented in JavaScript (ECMAScript). However, read
the final chapter if you are interested in implementations in other languages.
In this chapter we will go to the basics of the application: the project
structure and packages we used.
The project will be using the following packages:
Package name
Description
express
For the HTTP server and routing
openai
For all the OpenAI stuff
sass
To convert the SASS style files to CSS files
ws
For the WebSockets
The project structure is as follows:
Path
Description
public
The exposed directory to internet under the static name
public/audio
The directory containing public audio files
public/img
The directory containing public images
public/index.html
The entrypoint
style
The directory containing the style of the page
version-1
The naive implementation source code directory
version-2
The better implementation source code directory
The project can be seen
here
and where a code will be listed will also
contain the relative path to where that code can be found.
Run npm install followed by a npm run build to convert the SASS file to
CSS and you are ready to go.
To start the naive implementation run npm run start-v1 or to run the better
implementation, run npm run start-v2. Don't forget to define the environment
variable OPENAI_API_KEY.
On UNIX systems you can run:
OPENAI_API_KEY=YOU_API_KEY npm run start-v1`
And on Windows:
set OPENAI_API_KEY=YOU_API_KEYnpm run start-v1
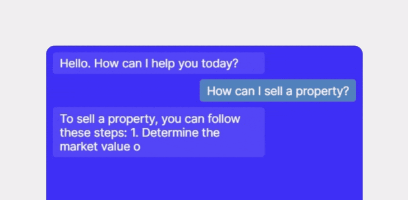
This is the page you should see when you access the page:
Once the user hits the enter key and the input is not empty, we will disable
both the text input and the audio button so the user won't send another
message while we getting a response to the previous message. Once we get the
answer we restore the functionality.
After we disable the input, we call the main function, addMessage, which does
the magic. Let's look at it:
/* version-1/client.js *//** * Add a new message to the chat. * @async * * @param {MessageType} type the type of message * @param {String|Audio} message the data of the message * @param {Object} [settings] additional settings * @param {Number} [settings.audioLength] the length of the audio in seconds * @returns {Promise} the promise resolved when all is done */async function addMessage(type, message, settings = {}) { const newMsg = document.createElement('div'); newMsg.classList.add('message'); if (type === MessageType.User) { newMsg.classList.add('user'); newMsg.innerHTML = message; } else if (type === MessageType.UserAudio) { newMsg.classList.add('user', 'audio'); newMsg.innerHTML = 'Audio message'; } else { newMsg.classList.add(MessageType.Bot); } const msgsCnt = document.getElementById('friendly-bot-container-msgs'); msgsCnt.appendChild(newMsg); // Keeping own history log if (type === MessageType.User || type === MessageType.Bot) { messageHistory.push({ role: type === MessageType.User ? 'user' : 'assistant', content: message }); } if (type === MessageType.Bot) { if (Settings.UseWriteEffect) { // Create a write effect when the bot responds let speed = Settings.DefaultTypingSpeed; if (settings.audioLength) { const ms = settings.audioLength * 1000 + ((message.match(/,/g) || []).length * 40) + ((message.match(/\./g) || []).length * 70); speed = ms / message.length; } for (let i=0, length=message.length; i < length; i += 1) { newMsg.innerHTML += message.charAt(i); await sleep(speed); } } else { newMsg.innerHTML = message; } } else if (type === MessageType.User || type === MessageType.UserAudio) { let response; if (type === MessageType.User) { response = await sendMessage({ message }); } else if (type === MessageType.UserAudio) { response = await sendMessage({ audio: message }); } if (response.audio) { const audio = convertBase64ToAudio(response.audio); playAudio(audio); } return addMessage(MessageType.Bot, response.answer); }}
The function will create a new HTMLDivElement for the new message and add the
CSS class based on the type of the message.
Once that is done we store the message in our client-side chat history.
Next, if the message to be added is from the bot, we display it using a
"writing effect". We try to synchronize the audio, if it exists, to the typing
speed by dividing the length of the audio to the number of characters in the
message.
If the message added is from the user then, we send it to the server to get the
answer from AI by calling the function sendMessage.
The function sendMessage just makes an HTTP request using fetch to our
server.
One thing to mention: we generate a random ID for each client that we send with
each message so the server knows from where to get the chat history.
The alternative to sending an identifying ID to the server would be to send
the whole history each time, but with each message the data that needs to be
sent increase.
/* version-1/client.js *//** * Create a random ID of given length. * Taken from https://stackoverflow.com/a/1349426 * * @param {Number} length the length of the generated ID * @returns {String} the generated ID */function makeID(length) { let result = ''; const characters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789'; const charactersLength = characters.length; let counter = 0; while (counter < length) { result += characters.charAt(Math.floor(Math.random() * charactersLength)); counter += 1; } return result;}const ChatID = makeID(10);// .../** * Send a message to the server and return the JSON back. * @async * * @param {Object} data the data to send * @returns {Promise<Object>} the result from the server */async function sendMessage(data = {}) { try { const response = await fetch(Settings.APISendMessage, { method: "POST", headers: { "Content-Type": "application/json", }, body: JSON.stringify({ id: ChatID, ...data }), }); return response.json(); } catch (error) { console.error("Error:", error); }}
Before we go to the server side to see how it handles the request, let's see
what happens when the user clicks on the audio button:
It is very similar to the text input handling. The function recordUserAudio
will return a base64 encoded audio, and we just cut the header of it before
sending it to addMessage.
The recordUserAudio function will try to get permissions from the user to
record audio and, if granted, will create a MediaRecorder and start recording.
We also will show some UI elements to let know the user we are recording their
voice and a button to stop the recording when done.
Once the stop button is hit, we convert the audio chunks to a Blob object and
the blob to a base64 encoded string and return it.
We also go through each audio track and stop them, then remove them. This is
necessary because, at least on Chrome, calling mediaRecorder.stop() will not
stop the "listening" state of the microphone.
Encoding the audio to base64 is not a very efficient method of sending the
audio to the server, but is a very easy method.
We will look on another method to send the audio to the server in
The better implementation section.
/* version-1/client.js *//** * Record the user and return it as an base64 encoded audio. * @async * * @param {HTMLElement} stopRecordButtonElement the stop button element * @returns {Promise<String>} the base64 encoded audio */async function recordUserAudio(stopRecordButtonElement) { let stream; try { stream = await navigator.mediaDevices.getUserMedia({ audio: true }); } catch (error) { console.error(`The following getUserMedia error occurred: ${error}`); return; } let chunks = []; const mediaRecorder = new MediaRecorder(stream, { mimeType: Settings.ClientAudioMimeType }); return new Promise((resolve, reject) => { const onStopClick = () => { mediaRecorder.stop(); stopRecordButtonElement.classList.remove('show'); }; mediaRecorder.addEventListener('dataavailable', (event) => { chunks.push(event.data); }); mediaRecorder.addEventListener('stop', (_event) => { const blob = new Blob(chunks, { type: Settings.ClientAudioMimeType }); chunks = []; const base64AudioPromise = blobToBase64(blob); stopRecordButtonElement.removeEventListener('click', onStopClick); // Stop the audio listening stream.getAudioTracks().forEach((track) => { track.stop() stream.removeTrack(track); }); base64AudioPromise.then(resolve).catch(reject); }); stopRecordButtonElement.classList.add('show'); mediaRecorder.start(); stopRecordButtonElement.addEventListener('click', onStopClick); })}
Let's look now how the request is handled on the server:
/* version-1/server.js */app.post('/api/message', async (req, res) => { if (!req.body.message && !req.body.audio) { res.status(400).send('Missing "message" or "audio"'); } if (req.body.message && req.body.audio) { res.status(400).send('Cannot be both "message" and "audio"'); } if (!req.body.id) { res.status(400).send('Missing "id"'); } const messages = getChatMessages(chatHistory, req.body.id); if (req.body.message) { messages.push({ role: "user", content: req.body.message }); } else { let content; try { content = await stt(openai, req.body.audio); } catch (error) { console.error(`(ChatID: ${req.body.id}) Error when trying to convert the user's audio to text:`); console.error(error); res.status(500).end(); return; } messages.push({ role: "user", content }); } let answer; try { answer = await getAnswer(openai, messages); } catch (error) { console.error(`(ChatID: ${req.body.id}) Error when trying to get an answer from ChatGPT:`); console.error(error); res.status(500).end(); return; } let audio; if (Settings.CreateAudioOfAnswer) { try { audio = await tts(openai, answer); } catch (error) { console.error(`(ChatID: ${req.body.id}) Error when trying to convert the ChatGPT's answer to audio:`); console.error(error); res.status(500).end(); return; } } messages.push({ role: "assistant", content: answer }); res.json({ answer, audio });});
After we check that the client sent the required data, we get the chat history
for the given ID (or create a new chat history):
/* version-1/server.js *//** * Get the chat history, or create a new one or the given ID. * * @param {Object} chatHistory the global chat history object containing all the chats * @param {String} id the ID of the chat to retrieve * @returns {Object} the chat history for the given `id` */function getChatMessages(chatHistory, id) { if (!chatHistory[id]) { chatHistory[id] = [ { role: "system", content: Settings.AISystemContent }, { role: "assistant", content: Settings.WelcomeMessage } ]; } return chatHistory[id];}
Then, if the received message is a text, not an audio, we add the message to the
chat history. If the received message is an audio, we call the function stt
that will perform the speech-to-text action using OpenAI's Whisper.
The function will use the openai.audio.transcriptions.create method. The main
parameter of this method is file, which must represent our audio data. We use
the toFile function from the package openai/uploads to convert our base64
encoded audio file to a file that OpenAI can read. The function will return the
transcription of the given audio.
/* version-1/server.js *//** * Convert speech to text using OpenAI. * @async * * @param {OpenAI} openai the OpenAI instance * @param {String} audio the base64 encoded audio * @returns {Promise<String>} the text */async function stt(openai, audio) { // Documentation https://platform.openai.com/docs/api-reference/audio/createTranscription const transcription = await openai.audio.transcriptions.create({ file: await toFile(Buffer.from(audio, 'base64'), `audio.${Settings.ClientAudioExtension}`), model: Settings.STTModel, language: Settings.ClientAudioLanguage, // this is optional but helps the model }); return transcription.text;}
Now that we have the message, we send the chat to ChatGPT and wait for a
response by calling the getAnswer function.
Last part is about converting the response from the AI to an audio using the
function tts that uses the method openai.audio.speech.create to create
an audio file. The OpenAI's TTS support multiple formats but we've chosen mp3
for this tutorial.
Once the audio data is got we convert it into a Buffer and from there to a
base64 encoded audio string to send back to the client.
But can we make it better? Well, yes. Instead of using HTTP requests, we can
instead use WebSockets to communicate between the client and the server and
tell ChatGPT to return the results as a stream. In this way, we can create
a real-time writing effect because we will stream the result from ChatGPT to
the client in real time.
So let's look at some code. We started from the previous implementation and
changed what was needed to support WebSockets.
/* version-2/client.js */const ws = new WebSocket(Settings.WSAddress);const ChatID = makeID(10);// When the connection to the server is made send the chat IDws.addEventListener('open', () => { const idMessage = new Uint8Array([ClientMessageID.SetClientID, ...new TextEncoder().encode(ChatID)]); ws.send(idMessage);});
In this section of the client code, we connect to the WebSocket server. When the
connection is opened, we send the chat ID as the first message so the server
knows who we are.
The structure of the data/messages sent between the client and the server
follows this format:
The first byte represents the type of the message we are sending, allowing the
server to know how to handle the payload represented by the following bytes in
the data sent.
Note that we configured the WebSocket server to accept and send only
binary data. This is why we will always send a Uint8Array from the client
side and a Buffer from the server side.
We are sending only in binary because it is more efficient, converting to text
only what we need and remaining to stay in binary (like the audio chunks, what
need to remain in binary).
In the following code, we handle the messages received from the server side:
/* version-2/client.js */const subscriptionsToWSMessages = [];ws.addEventListener('message', async (event) => { const data = new Uint8Array(await event.data.arrayBuffer()); const messageType = data[0]; // Because we know all the possible messages are all strings we can convert all the payloads to string const content = new TextDecoder().decode(data.slice(1)); if (!ws.allGood && messageType !== ServerMessageID.OK) { if (messageType === ServerMessageID.Error) { console.error('Something wrong sending the chat ID:', content); } } else if (messageType === ServerMessageID.OK) { ws.allGood = true; } else { let done; for (let i=0, length=subscriptionsToWSMessages.length; i < length; i += 1) { done = await subscriptionsToWSMessages[i](messageType, content); if (done === true) return; } if (!done) { if (messageType === ServerMessageID.Error) { console.error('Unhandled error received from server:', content); } else { console.log(`Unknown message type "${messageType}" received.`); } } }});
Since we know that all the messages we receive from the server side are texts,
we can safely convert the entire payload to a String using TextDecoder:
new TextDecoder().decode(data.slice(1));.
First we will wait for the first ServerMessageID.OK from the server, which
represents that the sent chat ID is valid.
To be flexible, we use an array of functions that represent listeners to the
messages received from the server. This allow us to be modular in our approach.
Each function must return true or false: true means that the message was
processed, and it is not necessary to call the rest of the subscribed functions.
To make it easy to add and remove subscribers, we extend our ws object with
the following:
/* version-2/client.js *//** * Add a function to the list of functions to be called when the socket receives * a new message. The function must return a boolean: if `true` is returned then * is considered that the message was handled and will stop the execution of the * rest of the subscribers in the list. * * @param {Function} fn the function to be added */ws.subscribeToWSMessage = (fn) => { subscriptionsToWSMessages.push(fn);}/** * Remove an added function from the list of subscribers. * * @param {Function} fn the function to be removed */ws.unsubscribeToWSMessage = (fn) => { subscriptionsToWSMessages.splice(subscriptionsToWSMessages.indexOf(fn), 1);}
Next, we extend again the ws object with 3 more methods:
sendTextMessage for sending the user's text message;
sendAudioChunk for sending an audio chunk from the user's voice recording;
sendAudioEnd for telling the server that the audio is done.
/* version-2/client.js *//** * Send a text message to the server. * @async * * @param {String} message the message to send * @param {Function} onNewMessageContent the function to be called with the new answer from bot as it sent from the server */ws.sendTextMessage = async (message, onNewMessageContent) => { ws.createSubscriptionForBotResponse(onNewMessageContent); const wsMessage = new Uint8Array([ClientMessageID.UserTextMessage, ...new TextEncoder().encode(message)]); ws.send(wsMessage);};
The sendTextMessage method accepts the message that needs to be sent to the
server and a function that will be called multiple times with the stream of data
received from ChatGPT.
In this method, before sending the message to the server, we call the
createSubscriptionForBotResponse method, which handles creating and adding a
subscription to listen for new messages to handle the response from the bot.
/* version-2/client.js *//** * Create and add a subscription to listen for the response of the bot to our sent message * * @param {Function} onNewMessageContent the function to be called with the new answer from bot as it sent from the server */ws.createSubscriptionForBotResponse = (onNewMessageContent) => { const wsMessagesHandler = (messageType, content) => { if (messageType === ServerMessageID.TextChunk) { onNewMessageContent(content); return true; } else if (messageType === ServerMessageID.TextEnd) { ws.unsubscribeToWSMessage(wsMessagesHandler); return true; } return false; } ws.subscribeToWSMessage(wsMessagesHandler);}
The subscribed function will check if the received message from the server has
the required message type for the bot's response (ServerMessageID.TextChunk).
If it does, we call the received function with the text chunk, which will add
the chunk to the current bot response in the chat.
When the bot is done with the response, the server will send us a message with
type ServerMessageID.TextEnd, indicating that we can stop listening, at which
point we will unsubscribe from listening to new messages.
/* version-2/client.js *//** * Send an audio chunk to the server. * @async * * @param {Blob} blobChunk the audio blob chunk */ws.sendAudioChunk = async (blobChunk) => { const wsMessage = new Uint8Array([ClientMessageID.UserAudioChunk, ...new Uint8Array(await blobChunk.arrayBuffer())]); ws.send(wsMessage);};/** * Tell the server that the audio is done. * * @param {Function} onNewMessageContent the function to be called with the new answer from bot as it sent from the server */ws.sendAudioEnd = (onNewMessageContent) => { ws.createSubscriptionForBotResponse(onNewMessageContent); ws.send(new Uint8Array([ClientMessageID.UserAudioEnd]));};
The next 2 methods, sendAudioChunk and sendAudioEnd, are for sending the
recorded voice of the user to the server. The first one, sendAudioChunk, will
send the received bytes to the server, while the other one, sendAudioEnd, will
send a message to the server indicating that the audio is done and, like the
sendTextMessage method, will call createSubscriptionForBotResponse to listen
for the response from the bot.
Next we will look at how the onNewMessageContent parameter from the
sendTextMessage and sendAudioEnd methods is sent.
We slightly modified the addMessage function by splitting it into
addUserMessage and addBotMessage. We will just look at addUserMessage:
/* version-2/client.js *//** * Add a new message to the chat. * @async * * @param {WebSocket} ws the WebSocket * @param {MessageType} type the type of message * @param {String|Audio} message the data of the message * @returns {Promise} the promise resolved when all is done */async function addUserMessage(ws, type, message) { createMessageHTMLElement(type, type === MessageType.User ? message : 'Audio message'); // Keeping own history log if (type === MessageType.User) { messageHistory.push({ role: type === MessageType.User ? 'user' : 'assistant', content: message }); } if (type === MessageType.User) { await ws.sendTextMessage(message, addBotMessageInChunks()); } else { await ws.sendAudioEnd(addBotMessageInChunks()); }}/** * Add bot message in chunks. The functions returns another function that when called with * the argument will add that argument to the bot message. * * @returns {Function} the function accept a parameter `content`; when called the `content` is added to the message */function addBotMessageInChunks() { const newMsg = createMessageHTMLElement(MessageType.Bot); let nextContentIndex = 0; let currentContentIndex = 0; let currentContentPromise; const onNewMessageContent = async (content) => { const thisContentIndex = nextContentIndex; nextContentIndex += 1; while (thisContentIndex !== currentContentIndex) { await currentContentPromise; } currentContentPromise = new Promise(async resolve => { await addContentToMessage(newMsg, content); currentContentIndex += 1; resolve(); }); } return onNewMessageContent;}
The addBotMessageInChunks function is responsible for creating and returning
the function that will append the given text/content to the current bot message.
Because we want to have a writing effect to the bot message as it comes in, we
need to have a method to synchronize everything. The server will send the text
as it comes, and the addContentToMessage function, which is responsible for
creating the writing effect, may not be ready in time to handle the next
received text.
So, we came up with a simple synchronization mechanism: we create 2 counters and
a variable that will hold a promise. Each time the returned function is
called we assign to that call the next index (line 39) and then increase the
counter. The function will wait for its turn by waiting for the promise to be
resolved, and when it is its turn, it will overwrite the promise variable with a
new promise that will just wait for the writing effect to be done (line 47) and
then increase the counter.
/* version-2/client.js *//** * Record the user and send the chunks to the server and on end wait for all the chunks to be sent. * @async * * @param {WebSocket} ws the WebSocket * @param {HTMLElement} stopRecordButtonElement the stop button element * @returns {Promise} */async function recordUserAudio(ws, stopRecordButtonElement) { let stream; try { stream = await navigator.mediaDevices.getUserMedia({ audio: true }); } catch (error) { console.error(`The following getUserMedia error occurred: ${error}`); return; } const mediaRecorder = new MediaRecorder(stream, { mimeType: Settings.ClientAudioMimeType }); return new Promise((resolve, _reject) => { const onStopClick = () => { mediaRecorder.stop(); stopRecordButtonElement.classList.remove('show'); }; // Create an array to store the promises of the sent audio chunks so we can make sure that // when the user hit the stop button all the audio chunks are sent const sentAudioChunksPromises = []; mediaRecorder.addEventListener('dataavailable', (event) => { sentAudioChunksPromises.push(ws.sendAudioChunk(event.data)); }); mediaRecorder.addEventListener('stop', async (_event) => { await Promise.all(sentAudioChunksPromises); // Stop the audio listening stream.getAudioTracks().forEach((track) => { track.stop() stream.removeTrack(track); }); resolve(); }); stopRecordButtonElement.classList.add('show'); // The parameter of `start` is called `timeslice` and define how often, in milliseconds, // to fire the `dataavailable` event with the audio chunk mediaRecorder.start(1000); stopRecordButtonElement.addEventListener('click', onStopClick); })}
The function recordUserAudio was also changed sightly:
Calling mediaRecorder.start() with the argument 1000 will slice the user's
audio into chunks of 1 seconds, which will be received in the handler for
the dataavailable event;
The handler for the dataavailable event will add the promise returned by the
calling of ws.sendAudioChunk into an array so we can wait for all of them to
finish in the handler for the stop event of our MediaRecorder instance.
This is pretty much it for the client-side.
Now let's switch to the server side to see what was added:
/* version-2/server.js */const webSocketServer = new WebSocketServer({ port: Settings.WSPort });webSocketServer.on('connection', function connection(clientWS) { // Array to keep all the audio chunks until the user is done talking clientWS.audioChunks = []; clientWS.on('error', console.error); clientWS.on('message', async (data, isBinary) => { // ... });});
We are creating the WebSocket server (using the ws package) with our defined
port. Once we have a connection, we add an empty array called audioChunksto
the client socket, which will hold the audio buffer chunks.
When the user send a message, we do the following:
/* version-2/server.js */// ...// If the message is non-binary then reject it.// If the user did not already set the chatID then we close the socket.if (!isBinary) { const errorMsg = 'Only binary messages are supported.'; clientWS.send(Buffer.from([ServerMessageID.Error, errorMsg])); console.error(`(ChatID: ${clientWS.chatID}) Non-binary message received.`); if (!clientWS.chatID) { clientWS.close(1003, errorMsg); } return;}const messageType = data[0];const payload = data.slice(1);if (!clientWS.chatID && messageType !== ClientMessageID.SetClientID) { clientWS.send(Buffer.from('Error! Please send first your ID'));} else if (messageType === ClientMessageID.SetClientID) { const id = payload.toString('utf8'); if (typeof id === 'string' && id.trim() !== '') { clientWS.chatID = id; clientWS.send(Buffer.from([ServerMessageID.OK])); } else { clientWS.send(Buffer.from([ServerMessageID.Error, ...Buffer.from('Error! Invalid ID. Please send a valid string ID.')])); }}// ...
First, we check if the received message is in binary. After that, we
separate the message type (messageType) from the rest of the data (payload).
If the client hasn't sent the chat ID yet and the message type is not for
this, then return an error. Otherwise, we store the chat ID if is correct inside
the client socket.
/* version-2/server.js */// ...} else if (messageType === ClientMessageID.UserTextMessage || messageType === ClientMessageID.UserAudioEnd) { const messages = getChatMessages(chatHistory, clientWS.chatID); let messageContent; if (messageType === ClientMessageID.UserTextMessage) { messageContent = payload.toString('utf8'); } else if (messageType === ClientMessageID.UserAudioEnd) { // When the client send the `ClientMessageID.UserAudioEnd` message type it means it clicked the STOP button // Concat all the buffers into a single one const buffer = Buffer.concat(clientWS.audioChunks); // Reset the chunks array clientWS.audioChunks = []; // Send audio to OpenAI to perform the speech-to-text messageContent = await stt(openai, buffer); } messages.push({ role: "user", content: messageContent }); try { await getAnswer(openai, messages, clientWS); } catch (error) { console.error(`(ChatID: ${clientWS.chatID}) Error when trying to get an answer from ChatGPT:`); console.error(error); clientWS.send(Buffer.from([ServerMessageID.Error, ...Buffer.from('Error!')])); return; }}// ...
Once the client send a message of type ClientMessageID.UserTextMessage or
ClientMessageID.UserAudioEnd, we retrieve, as before, the chat's messages. If
the message is of type ClientMessageID.UserTextMessage, we will convert the
received data (payload) to a String. If the message is of type
ClientMessageID.UserAudioEnd, we will combine all the audio buffer chunks into
a single chunk, reset the array of chunks and perform the speech-to-text action
on the audio, which will return the text.
Next step is to create the new message in the format accepted by ChatGPT and
query ChatGPT for a response.
The last message type we handle is for the audio chunks, which just adds the
received data to the audio chunks array of the client socket.
Now lets look over how the getAnswer function was changed in order to support
streams:
/* version-2/server.js *//** * Get the next message in the conversation * @async * * @param {OpenAI} openai the OpenAI instance * @param {String[]} messages the messages in the OpenAI format * @returns {String} the response from ChatGPT */async function getAnswer(openai, messages, clientWS) { // Documentation https://platform.openai.com/docs/api-reference/chat/create const stream = await openai.chat.completions.create({ model: Settings.ChatGPTModel, messages, stream: true, }); for await (const chunk of stream) { const content = chunk.choices[0]?.delta?.content; if (!content) continue; clientWS.send(Buffer.from([ServerMessageID.TextChunk, ...Buffer.from(content || "")])); } clientWS.send(Buffer.from([ServerMessageID.TextEnd]));}
By simply adding stream: true to the object sent as argument to ChatGPT, it
will return a stream object that we can loop through. For each non-empty chunk
of data, we will send it back to the client. After the stream is
done, we need to notify the client that the response is complete.
Tips for adding the TTS functionality back
Ok, ok, but what if we have a TTS service that supports streaming or accepts
many requests that are processed fast?
No problem: we just need to adjust some things on the server side and client
side.
On the server side, once we receive a chunk of the answer from the AI (in the
getAnswer function), we need to call our TTS service and send the audio data
received as response to the client side.
On the client side, more changes are needed:
We cannot, no more, always transform the received data to text because now
we can receive audio data;
Because we might receive the next audio data before the previous audio is done
playing, we need to introduce a synchronization method to keep track of which
audio needs to be played next.